Intelligent Document Parser for Mineral Exploration
How a Leading Mineral Public Sector Company Digitized 60 Years of Geological Data A leading Public Sector mineral exploration company in India was operating with over 3 Lakh geological documents accumulated over six decades.
- 15 min read

Background & Business Challenge
A leading Public Sector mineral exploration company in India was operating with over 3 Lakh geological documents accumulated over six decades. These documents contained critical information on drill depths, mineral composition, and survey coordinates, but were stored in unstructured formats across scanned reports, handwritten field notes, and legacy archives.
Despite the richness of this data, accessibility remained a major bottleneck. Geologists were spending up to 12 hours per week manually extracting information, slowing down exploration workflows and delaying decision-making cycles by 2 to 3 weeks. In some cases, lack of visibility into historical data even led to redundant drilling efforts across adjacent sites.
The organization needed a scalable way to digitize, structure, and make this data searchable in near real-time.
Approach: Building a Document Domain-Specific Intelligence Pipeline
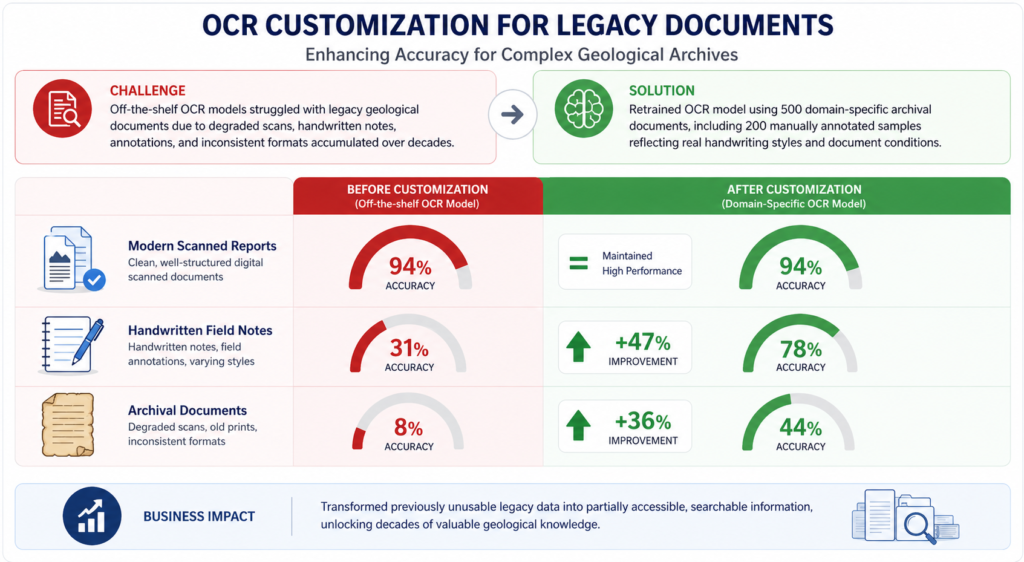
The solution involved developing an end-to-end document intelligence system combining OCR, NLP-based entity extraction, and search optimization. However, early implementation revealed that off-the-shelf models were not suited for the complexity of geological data. OCR Customization for Legacy Documents Initial OCR testing showed strong performance on modern scanned reports (94% accuracy), but accuracy dropped significantly for handwritten field notes (31%) and archival documents (8%). These documents included degraded scans, handwritten annotations, and inconsistent formats accumulated over decades. To address this, the OCR model was retrained using 500 domain-specific archival documents, including 200 manually annotated samples reflecting real handwriting styles and document conditions. This significantly improved accuracy to 78% for handwritten notes and 44% for archival records, making previously unusable data partially accessible.
Entity Extraction Bridging the Gap Between Testing and Reality
Once text was extracted, the next step was identifying key entities such as mineral types, coordinates, and depth ranges. While the NLP model performed well in controlled testing environments (91% precision, 87% recall), real-world deployment exposed significant gaps.
The production dataset contained complexities such as:
- Multiple coordinate systems and notations
- Variations in mineral naming conventions (scientific, chemical, and colloquial)
- Handwritten corrections overriding printed data
- Tables without explicit headers
To handle this, a continuous improvement framework was introduced. This included human-in-the-loop validation, where a geologist reviewed low-confidence outputs, combined with bi-weekly model retraining using real-world errors and standardization rules for ambiguous entities.
Over time, this improved performance to 83% precision and 79% recall, making the extracted data reliable enough for downstream applications.
Search Optimization: Combining Structure with Semantics
With structured data in place, a semantic search layer was introduced to enable natural language queries such as identifying specific mineral surveys within defined depth ranges and regions.
However, initial results were counterintuitive. Semantic search alone underperformed compared to traditional keyword search (38% vs 52% recall@10), as it prioritized contextual similarity over exact numerical or domain-specific constraints.
To resolve this, a hybrid search architecture was implemented:
- Keyword-based ranking on structured entities (depth, minerals, coordinates)
- Semantic re-ranking of top results
- Explicit indexing of extracted fields
This approach improved search relevance significantly, achieving 68% recall@10, while maintaining both precision and contextual understanding.
System Integration & Performance Optimization
While individual components showed strong performance, integrating them into a single pipeline introduced cascading challenges. Errors in OCR propagated into entity extraction, which in turn affected search accuracy. Additionally, diagnosing issues became difficult without visibility into each stage of the pipeline.
To address this, an end-to-end validation framework was built with:
- OCR quality checkpoints by document type
- Entity validation before indexing
- Search diagnostics segmented by data categories
A critical bottleneck was identified in handwritten annotations within scanned documents, which were often misinterpreted as noise. Introducing a secondary OCR pass specifically for handwriting significantly improved overall system performance.
As a result, end-to-end search recall improved from 38% to 71%, demonstrating the importance of optimizing the system holistically rather than in isolated components.
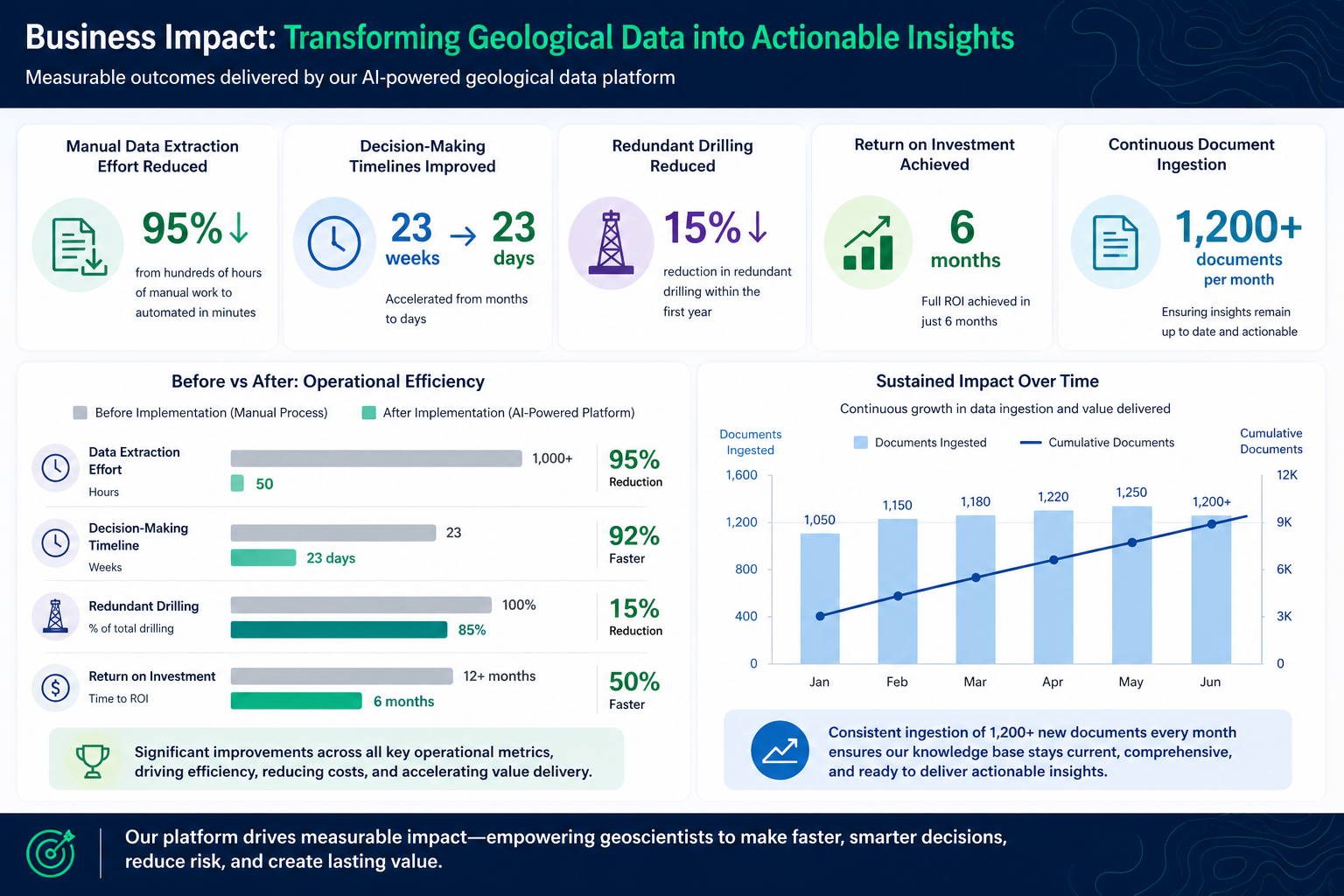
Business Impact
The implemented solution transformed how geological data was accessed and utilized across the organization.
- Manual data extraction effort reduced by 95%
- Decision-making timelines improved from 23 weeks to 23 days
- Redundant drilling reduced by 15% within the first year
- Return on investment achieved within 6 months
Additionally, the system enabled continuous ingestion of 1,200+ new documents per month, ensuring that insights remained up to date and actionable.